How VKG enables its employees to protect their data
As a trusted partner in the finance industry VKG needed an email solution that enabled them to send data easily and securely to their many clients

The General Data Protection Regulation (GDPR) is a European regulation. In the Netherlands, the GDPR replaces the Personal Data Protection Act. It has become mandatory for companies to keep closely monitor the security of their email traffic. The GDPR protects personal data regardless of the technology used for processing and storing that; in all cases, personal data is subject to the protection requirements set out in the GDPR.
You must ensure that the personal details of your employees, as well as customers, always remain completely secure.
The short answer is no. In our latest webinar, guest speaker Arie van der Deijl from Aareon conveyed the importance of production data and GDPR compliance. The GDPR applies to all organizations dealing with sensitive data, regardless of whether this is personal data, production data, or both. When production data is being duplicated to a testing environment in non-production, organizations must be able to ensure that this data is secure and GDPR compliant while they are improving their internal processes and efficiencies.
A company may note that their terms & conditions suggest they use data for testing purposes only. However, this does not justify its use and exposure. According to the GDPR, anything that falls into the category of personal data must and should still be protected.
Personal data is any information that relates to an identified or identifiable living individual. Different pieces of information, which collected together can lead to the identification of a particular person, also constitute personal data. A few examples of personal data are names, surnames, and home addresses.
Personal data that has been de-identified, encrypted or ‘pseudonymized’ but can be used to re-identify a person remains personal data and falls within the scope of the GDPR. Whereas personal data that has been rendered anonymous in such a way that the individual is not or no longer identifiable is no longer considered personal data. For data to be truly considered anonymised in accordance with the GDPR, the anonymisation must be irreversible.
To allow data to be used in testing or training, it must first be completely anonymized to the extent that it is irreversible. This is known as ‘Data Obfuscation’ (DO). This can officially be defined as a form of data masking where data is purposely scrambled to prevent unauthorized access to sensitive materials. This form of encryption results in unintelligible or confusing data. Masking is the primary means for data obfuscation. It is the process of scrambling, blurring, replacing existing data with data of approximate length and format.
Data masking is an important technique to develop a structure similar to the available one but has an inauthentic update on the company’s information which can be used for multiple reasons like user training and software testing. However, the main aim is to save the original data by having an operational substitute for various situations whenever the real data is not necessary.
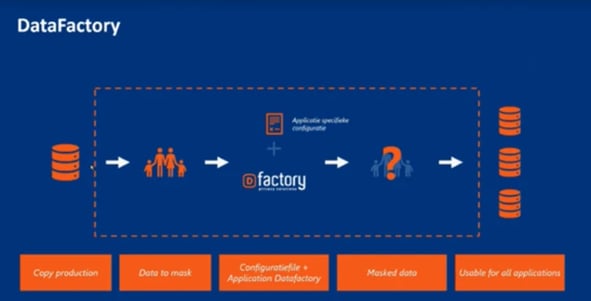
Source: Arie van der Deijl’s (Aareon) Presentation
Numerous data masking software have been developed to help organizations comply with regulations and continue to develop and improve their own work processes. Data masking can be executed in a number of ways. Each of these methods has its own pros and cons, with each method usually being best applied to a certain data type.
We’ve compiled a list of different data masking methods and their strengths and weaknesses below:
Adhering to old and new regulations still causes many problems in organizations today. Many organizations are unaware of data laws, while many continue to push their luck and run the risk of receiving heavy fines as a result.
Smartlockr takes this worry away by completely unburdening you, so that you as an organization can focus on what you are good at: your core business.
Want to know more about the GDPR?


As a trusted partner in the finance industry VKG needed an email solution that enabled them to send data easily and securely to their many clients
In healthcare, a lot of work is done with personal data. But there are dangers. You can read in this blog why this digitalization requires secure...